vitorcaldini.github.io
Data Analytics, Mineração de Dados e Machine Learning
Alguns notebooks de análises exploratórias e algoritmos construídos com Linguagem R e Python, os códigos para reprodução estão em todos os documentos.
A ideia é apresentar as análises em linguagem acessível e amigável a todos, assim como os algoritmos e o passo-a-passo. Espero que estimule novos enstusiastas da área.
Para acessar o caderno completo basta clicar no link do título.
(71) 98184-0456 │ caldini.civil@gmail.com
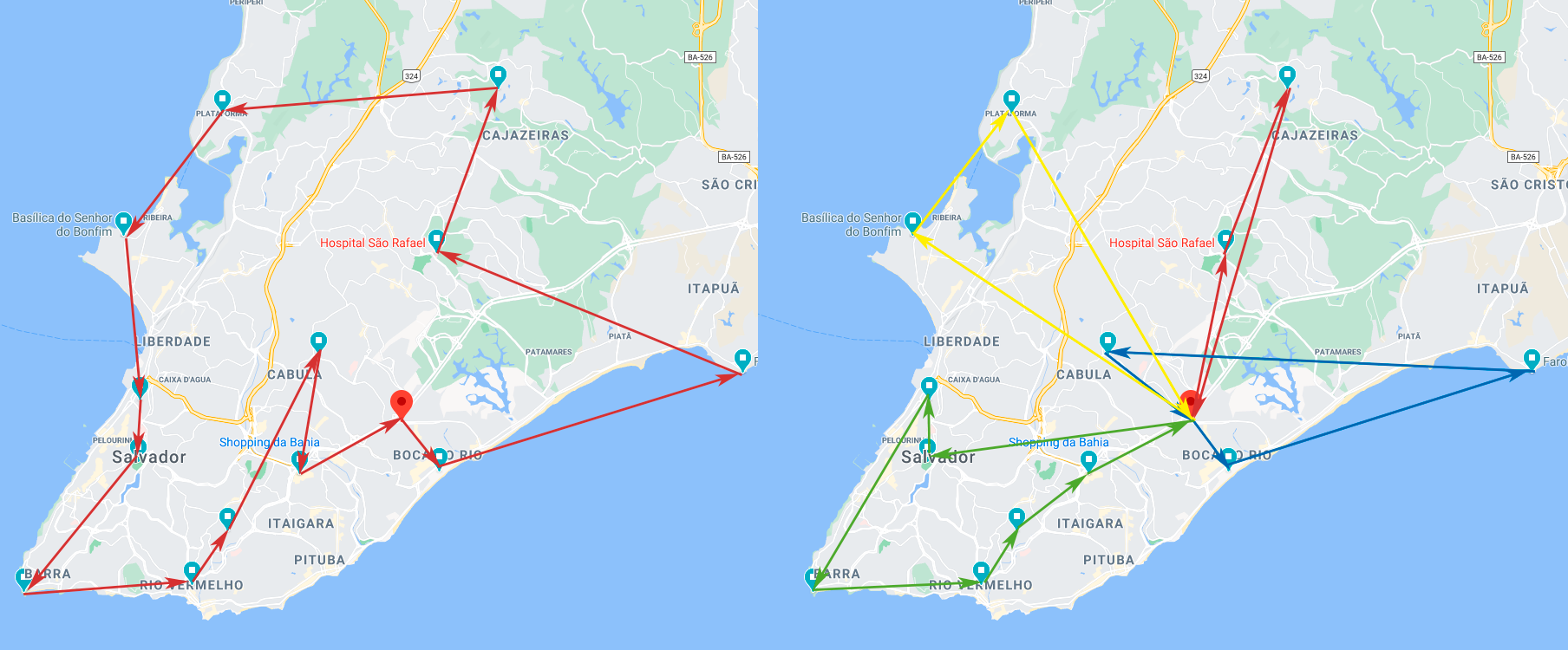
Supply Chain - Melhores Rotas
Teste de ferramentas de otimização de processos da Google Developers Experts (OR-Tools) para Pyhton, especialmente as soluções para rotas voltadas aos processo de supply chain.
São bem simples e trazem resultados interessantes. Em um teste com 1 depósito e 13 pontos de entrega existem mais de 3 bilhões de rotas possíveis para um único veículo (Problema do Caixeiro-Viajante - PCV), e a resposta é instantânea. Assim como no teste para 4 veículos (Vehicle Routing Problem).
E o mais importante: pelo teste ter usado conexão com a API Distance Matrix do Google Maps, as distâncias entre os pontos são reais (pelas próprias vias) e variam de acordo com o sentido da rota. E se em vez da rota mais curta quiser a mais rápida, a mesma API retorna a matriz de duração como dado de entrada do modelo.
Além disso, as ferramentas trabalham bem ao inserir as restrições da vida real, como: capacidade de carga de cada veículo e quantidade de entrega em cada destino, restrições de horário para chegada em cada ponto, planejamento e tempo de carga e descarga no depósito, entre outros.
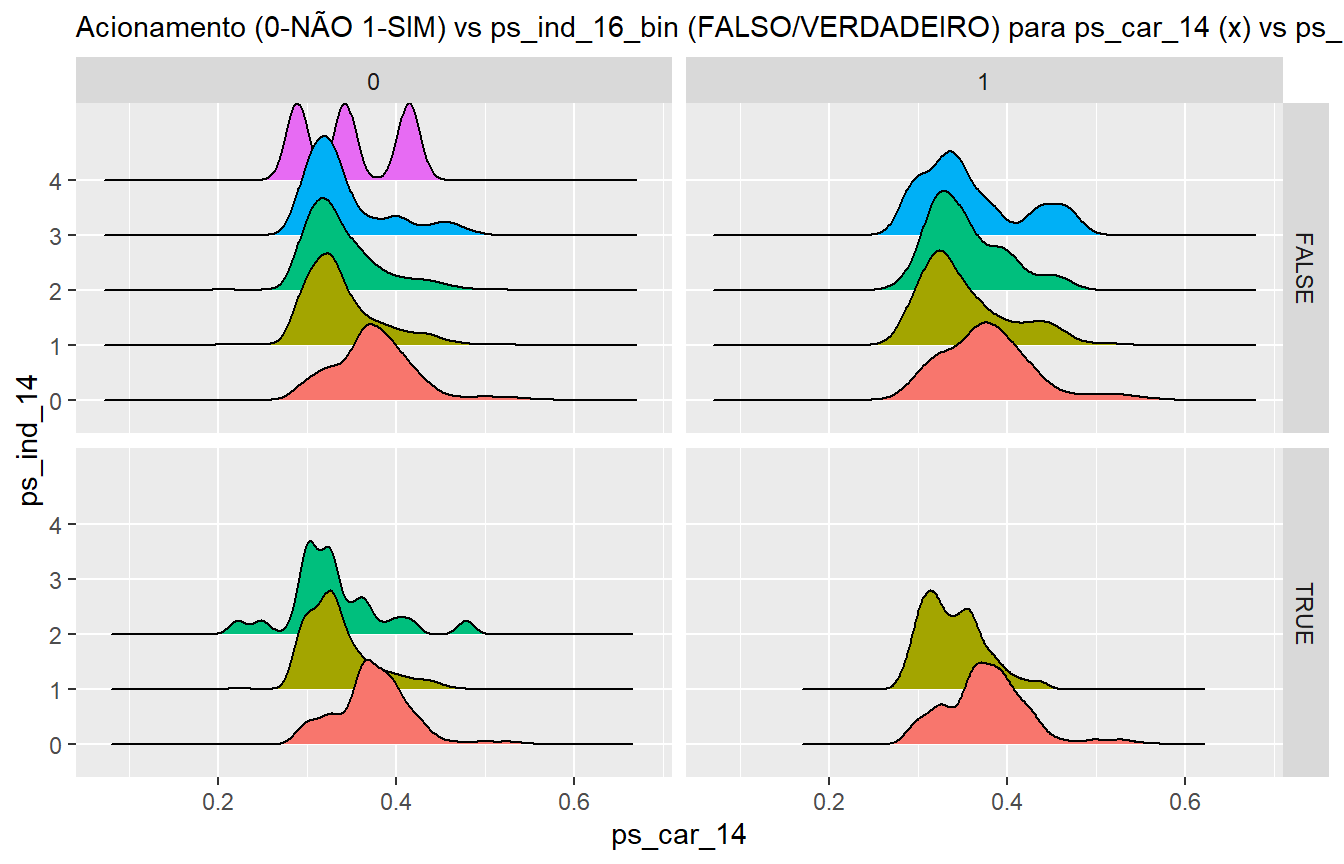
Porto Seguro - Estimativa de probabilidade de acionamento de seguro
Este documento apresenta uma Análise Exploratória de Dados (EDA) do conjunto de dados “Porto Seguro`s Safe Driver Prediction”, fornecido pela concessionária de seguros Porto Seguro como projeto de Machine Learning e com base nos Notebooks do projeto do Kaggle, especialmente do autor Headsortails. O documento visa apresentar uma análise detalhada dos dados coletados pela empresa e suas relações com a variável-alvo: saber se o cliente irá acionar o seguro no ano seguinte.
Não obstante, o desenvolvimento conta com uma seção de Feature Engineering, onde avalia a importância conjunta de variáveis para a estimativa da probabilidade de acionamento do seguro e, por fim, preparação dos dados para modelagem de algoritmos preditivos que estimam a probabilidade de cada cliente acionar o seguro no ano seguinte.
Um outro ponto importante foi a anonimização dos dados. Frente a vigência da LGPD esta é sempre uma questão que chama a atenção, e por isso escolhi deste conjunto de dados e eu espero que o desenvolvimento do estudo possa exemplificar etapas e obstáculos para o tratamento e análise de dados codificados para auxiliar analistas neste tipo de projeto que está cada vez mais comum.
Importância das características no preço de venda de imóveis e algoritmo para estimar valor
Consiste em uma Análise Exploratória de Dados (EDA), tratamento e preparação de dados (Data Wrangling), avaliação e seleção dos principais parâmetros (Feature Engineering) e modelagem de um algoritmo preditivo para estimativa de preço de venda de imóveis a partir dos algoritmos regressores por regularização Lasso e Gradient Boosting (XGBOOST).
O conjunto de dados utilizado é referente à cidade de Ames, em Iowa nos Estados Unidos. O estudo foi compilado por Dean De Cock e está disponível na plataforma Kaggle, bem como o notebook do autor Erik Bruin, utilizado como referência. O conjunto conta com 2919 residências, descritas por 79 características que serão ordenadas por sua importância no preço de venda do imóvel e manipuladas para modelagem do algoritmo preditivo.
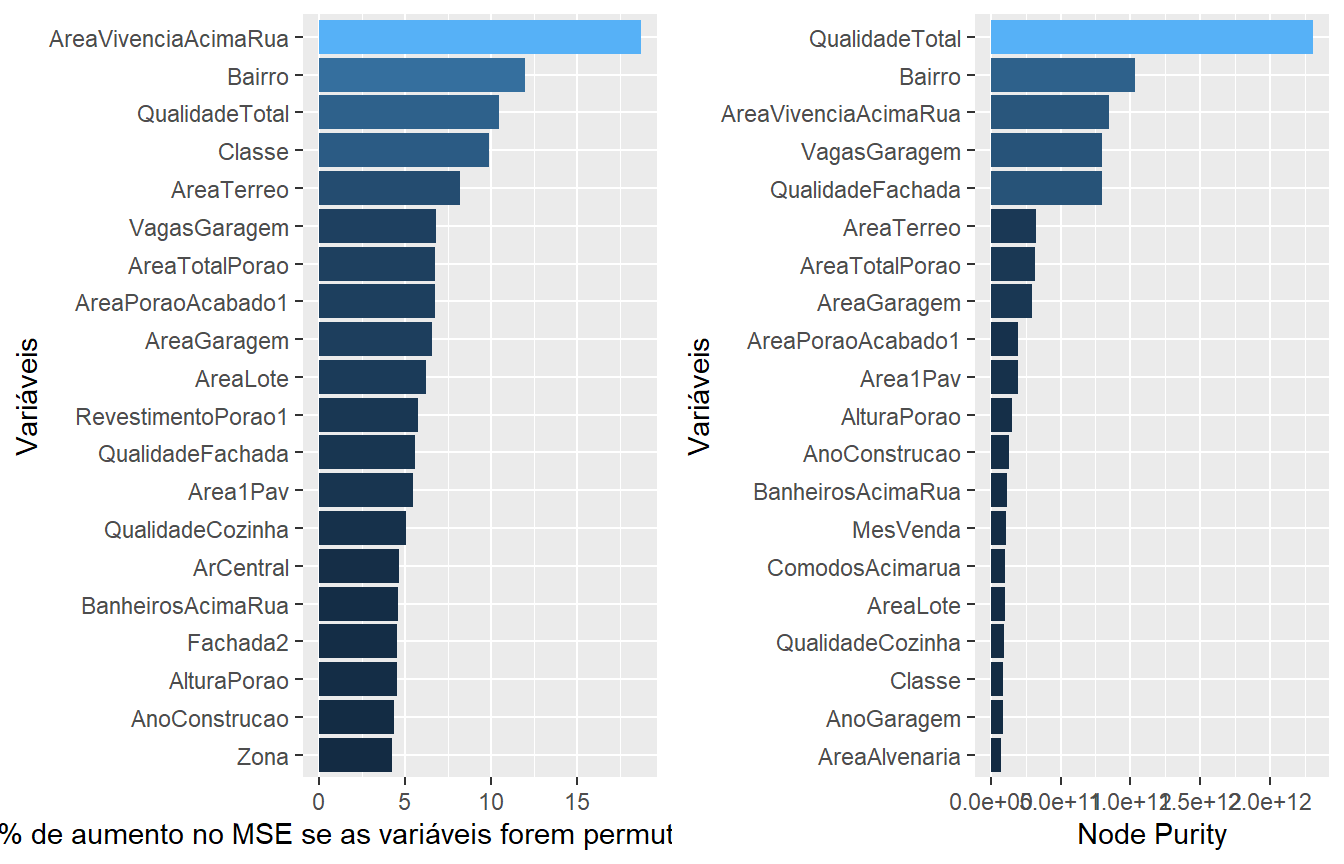
Este tipo de análise visa não somente a criação de um modelo matemático para previsão como também a descoberta de insights a respeito das variáveis que envolvem o mercado imobiliário estudado. Desta forma, entende-se que o estudo possa ser reproduzido para conjuntos de dados brasileiros e servir de direcionamento para ivestimentos de recursos e esforços de incorporadoras, construtores e imobiliárias que buscam aliar eficiência operacional, retorno financeiro e satisfação dos clientes.
Análise de Coorte (Cohort Analysis)
Empresas que enfrentam incertezas do mercado ou mudanças frequentes em seus produtos, serviços e processos precisar de métricas específicas que avaliem os diferentes momentos do ciclo de vida. E uma destas ferramentas é a Análise de Coorte (ou Análise Cohort).Presente em muitas plataformas como o Google Analytics, o princípio por trás da métrica é de que clientes de períodos diferentes vão ter experiências diferentes, por mais sutis que aparentam ser.
Por definição, um coorte é um grupo de indivíduos que compartilham a mesma característica, e a métrica permite avaliar o comportamento do coorte durante o tempo e compará-lo com outros coortes. Em uma de suas aplicações no setor de marketing/comercial, a análise divide os clientes de acordo com o período de aquisição do produto ou serviço e o seu ciclo de vida em um intervalo definido.
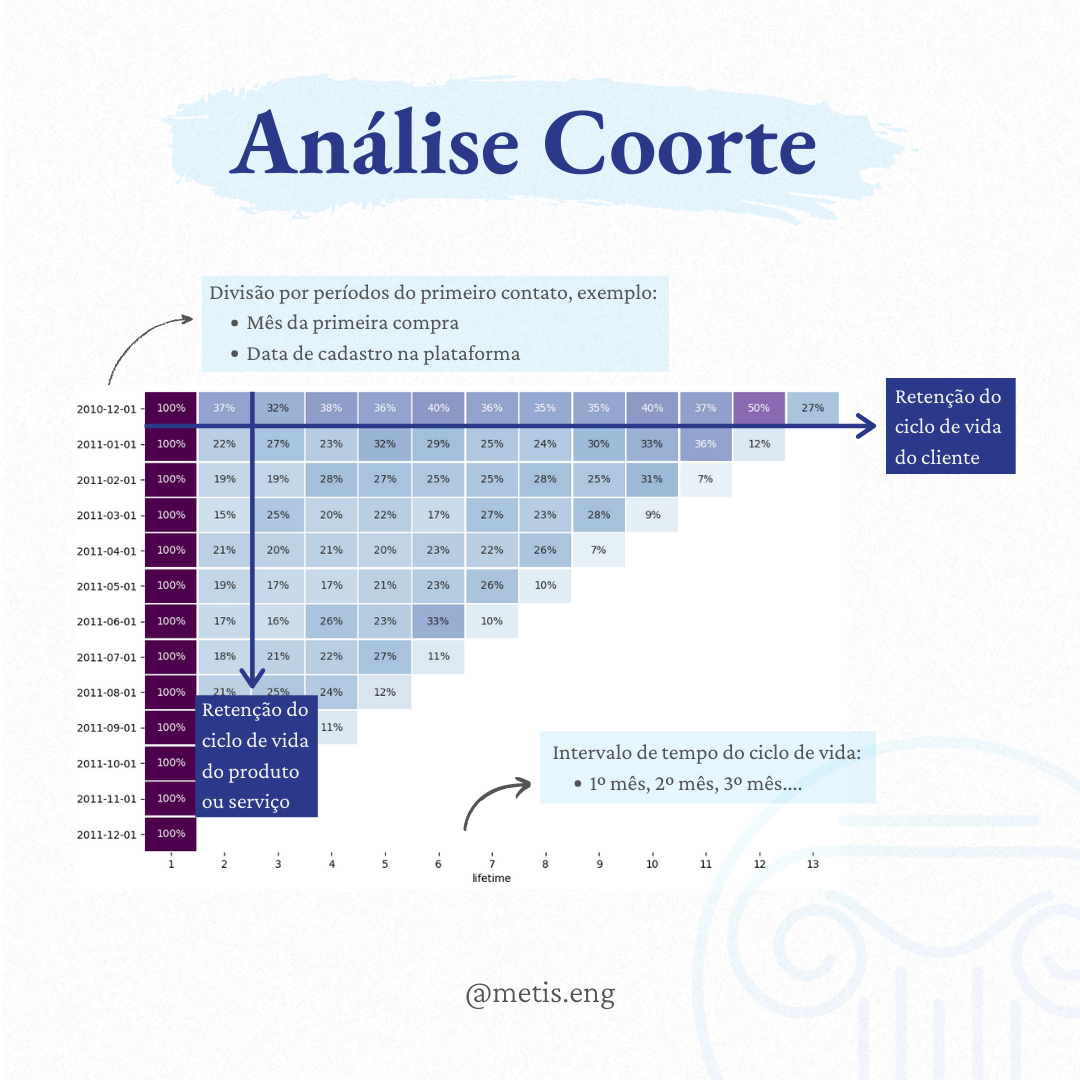
Assim, é possível analisar a retenção dos clientes durante o ciclo de vida do produto, e mais importante: durante o ciclo de vida do cliente, agrupado de acordo com o primeiro contato. Tudo isso de forma visual e intuitiva. Desta forma, as métricas ficam bastante granulares e permitem avaliar com precisão o impacto das alterações, investimentos e campanhas, por exemplo.
Separei um notebook resumindo e explicando o processo de criação da matriz a partir de uma planilha em excel com apenas 3 colunas: código da transação, data e código do cliente. Tem umas etapas bem breves de tratamento e limpeza de dados também, espero que tenha ficado acessível.
Análise RFM (Cohort Analysis)
A análise RFM é um modelo de clusterização de clientes que visa dividi-los em grupos para 3 características:
-
Recência Última vez que o cliente fez uma determinada ação (precisa ser definido pelo negócio), geralmente uma compra ou um engajamento específico;
-
Frequência Quantidade de ações (compras, engajamentos, etc) realizados pelo cliente em um intevalo de tempo definido.
-
Valor Monetário Quantia total gasta ou alguma quantificação de valor recebido do cliente.
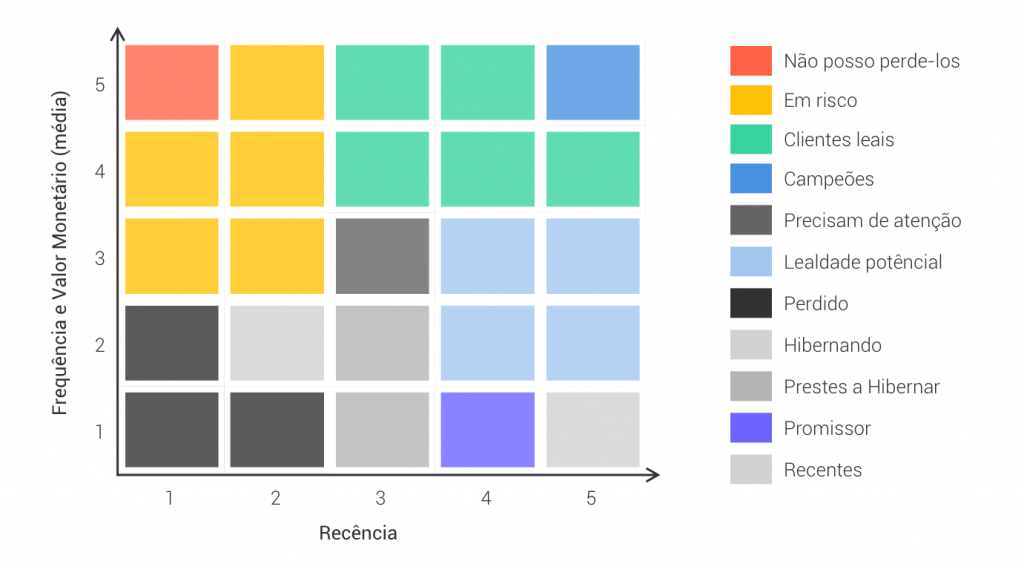
Neste notebook explico como criar uma matriz dessa e exportar em excel para encaminhar a estratégias específicas para cada cluster. Uma vez criado esse script, para cada planilha nova de entrada é só rodar os script novamente que sairá uma planilha em excel calculada e formatada de acordo com a matriz RFM.